概述
提示词(Prompts)是引导 AI 模型生成特定输出的输入内容,这些提示词的设计和措辞会显著影响模型的响应。
在 Spring AI 中,与 AI 模型交互的最低层级上,处理提示词的方式有些类似于在 Spring MVC 中管理”视图(View)”。这涉及创建包含动态内容占位符的大量文本,然后根据用户请求或应用程序中的其他代码来替换这些占位符。另一个类比就是包含占位符的 SQL 语句。
随着 Spring AI 的发展,它将引入更高层次的抽象来简化与 AI 模型的交互。本节描述的基础类在角色和功能上可以类比为 JDBC:
- ChatModel 类类似于 JDK 中的核心 JDBC 库。
- ChatClient 类可以类比为 JdbcClient,构建在 ChatModel 之上,通过 Advisor 提供更多高级构造,用于考虑与模型的过去交互、用额外的上下文文档增强提示词,以及引入代理行为。
提示词的结构在 AI 领域随着时间的推移不断演进。最初,提示词只是简单的字符串。后来,它们逐渐包含了特定输入的占位符,例如 AI 模型能识别的 “USER:”。OpenAI 通过将多个消息字符串在处理前按不同角色进行分类,为提示词引入了更结构化的形式。
提示词API能力
Prompt 类
ChatModel 的 call() 方法通常接受一个 Prompt 实例并返回 ChatResponse。
Prompt 类充当有组织的一系列 Message 对象和请求级 ChatOptions 的容器。每个 Message 在提示词中体现独特的角色,其内容和意图各不相同。这些角色可以涵盖从用户询问、AI 生成的响应到相关背景信息等各种元素。这种安排使得与 AI 模型的交互变得复杂而详细,因为提示词由多条消息构成,每条消息在对话中被分配了特定的角色。
以下是 Prompt 类的精简版本(为简洁起见省略了构造函数和工具方法):
1 | public class Prompt { |
Prompt 类提供了多种便捷方法来按角色访问消息:
这些方法在处理多轮对话或需要按角色处理消息时特别有用
单条消息访问:
| 方法 | 说明 |
|---|---|
getUserMessage() |
返回提示词中最后一条用户消息,如果不存在则返回空的 UserMessage |
getSystemMessage() |
返回提示词中第一条系统消息,如果不存在则返回空的 SystemMessage |
getLastUserOrToolResponseMessage() |
返回最后一条用户或工具响应消息,有助于保持对话连续性 |
多条消息访问:
| 方法 | 说明 |
|---|---|
getUserMessages() |
返回提示词中所有用户消息的列表,保持原有顺序 |
getSystemMessages() |
返回提示词中所有系统消息的列表,保持原有顺序 |
Message 接口
Message 接口封装了提示词的文本内容、一组元数据属性,以及一个称为 MessageType 的分类。
该接口定义如下:
1 | public interface Message { |
多模态消息类型还实现了 MediaContent 接口,提供一组 Media 内容对象。
Message 接口的各种实现对应于 AI 模型可以处理的不同类别的消息,模型根据对话角色区分消息类别,这些角色通过 MessageType 进行有效映射,如下所示:
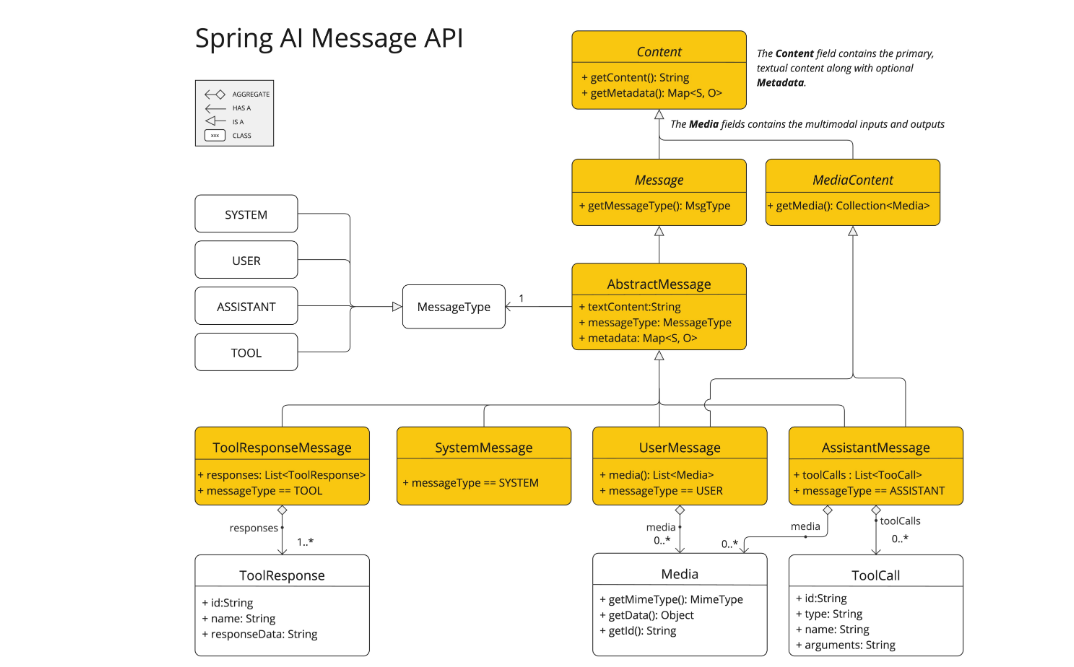
消息角色(Roles)
每条消息都被分配一个特定的角色。这些角色对消息进行分类,为 AI 模型阐明提示词每个部分的上下文和目的。这种结构化的方法增强了与 AI 沟通的细腻度和有效性,因为提示词的每个部分在交互中都扮演着独特且明确的角色。
- System Role(系统角色): 引导 AI 的行为和响应风格,设置 AI 如何解释和回复输入的参数或规则。这类似于在启动对话前向 AI 提供指令。
- User Role(用户角色): 代表用户的输入——他们对 AI 的问题、命令或陈述。这个角色是基础,因为它构成了 AI 响应的基础。
- Assistant Role(助手角色): AI 对用户输入的响应。不仅仅是答案或反应,它对维持对话流程至关重要。通过跟踪 AI 之前的响应(其”助手角色”消息),系统确保连贯且上下文相关的交互。助手消息还可能包含函数工具调用请求信息。这就像 AI 中的一个特殊功能,在需要时用于执行特定功能,如计算、获取数据或其他超越纯对话的任务。
- Tool/Function Role(工具/函数角色): 工具/函数角色专注于响应助手消息的工具调用请求而返回额外信息。
角色在 Spring AI 中以枚举形式表示,如下所示:
1 | public enum MessageType { |
提示词模板(PromptTemplate)
Spring AI 中提示词模板的一个关键组件是 PromptTemplate 类,旨在促进结构化提示词的创建,然后将其发送给 AI 模型进行处理。
该类使用 TemplateRenderer API 来渲染模板。默认情况下,Spring AI 使用 StTemplateRenderer 实现,它基于 Terence Parr 开发的开源 StringTemplate 引擎。模板变量通过 {} 语法进行标识,但你也可以配置分隔符以使用其他语法。
Spring AI 使用 TemplateRenderer 接口来处理变量到模板字符串的实际替换。默认实现使用 StringTemplate。如果需要自定义逻辑,你可以提供自己的 TemplateRenderer 实现。对于不需要模板渲染的场景(例如模板字符串已经完整),你可以使用提供的 NoOpTemplateRenderer。
该类实现的接口支持提示词创建的不同方面:
| 接口 | 说明 |
|---|---|
PromptTemplateStringActions |
专注于创建和渲染提示词字符串,代表提示词生成的最基本形式 |
PromptTemplateMessageActions |
专为通过生成和操作 Message 对象来创建提示词而定制的 |
PromptTemplateActions |
设计为返回 Prompt 对象,可传递给 ChatModel 以生成响应 |
虽然这些接口在许多项目中可能不会广泛使用,但它们展示了提示词创建的不同方法。
方法详解
PromptTemplateStringActions 方法:
| 方法 | 说明 |
|---|---|
String render() |
无需外部输入即可将提示词模板渲染为最终字符串格式,适用于没有占位符或动态内容的模板 |
String render(Map model) |
增强渲染功能以包含动态内容。使用 Map,其中键是提示词模板中的占位符名称,值是要插入的动态内容 |
PromptTemplateMessageActions 方法:
| 方法 | 说明 |
|---|---|
Message createMessage() |
无需额外数据即可创建 Message 对象,用于静态或预定义的消息内容 |
Message createMessage(List mediaList) |
使用静态文本和媒体内容创建 Message 对象 |
Message createMessage(Map model) |
扩展消息创建以集成动态内容,接受 Map,其中每个条目代表消息模板中的占位符及其对应的动态值 |
PromptTemplateActions 方法:
| 方法 | 说明 |
|---|---|
Prompt create() |
无需外部数据输入即可生成 Prompt 对象,适用于静态或预定义的提示词 |
Prompt create(ChatOptions modelOptions) |
无需外部数据输入但带有聊天请求特定选项的情况下生成 Prompt 对象 |
Prompt create(Map model) |
扩展提示词创建能力以包含动态内容,接受 Map,其中每个条目是提示词模板中的占位符及其关联的动态值 |
Prompt create(Map model, ChatOptions modelOptions) |
扩展提示词创建能力以包含动态内容,接受 Map 和聊天请求特定选项 |
使用示例
下面的示例展示了如何使用 SystemPromptTemplate 通过传入占位符值来创建具有系统角色的 Message。具有用户角色的消息随后与系统角色的消息组合形成提示词。然后将提示词传递给 ChatModel 以获取生成式响应。
1 | // 创建系统提示词模板 |
自定义模板渲染器
你可以通过实现 TemplateRenderer 接口并将其传递给 PromptTemplate 构造函数来使用自定义模板渲染器。你也可以继续使用默认的 StTemplateRenderer,但使用自定义配置。
1 | // 使用自定义配置 |
默认情况下,模板变量通过 {} 语法进行标识。如果你计划在提示词中包含 JSON,可能需要使用不同的语法以避免与 JSON 语法冲突。例如,你可以使用 < 和 > 分隔符。
从文件加载模板
Spring AI 支持 org.springframework.core.io.Resource 抽象,因此你可以将提示词数据放在文件中,直接在 PromptTemplate 中使用。例如,你可以在 Spring 管理的组件中定义一个字段来检索 Resource:
1 | ("classpath:prompts/system-prompt.st") |
然后直接将该资源传递给 SystemPromptTemplate:
1 | SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemPromptResource); |
提示词工程最佳实践
在生成式 AI 中,提示词的创建是开发人员的一项关键任务。这些提示词的质量和结构会显著影响 AI 输出的有效性。投入时间和精力设计精心构思的提示词可以极大地改善 AI 的结果。
分享和讨论提示词是 AI 社区的常见做法。这种协作方式不仅创造了共享的学习环境,还促成了高效提示词的识别和使用。
该领域的研究通常涉及分析和比较不同的提示词,以评估它们在各种情况下的有效性。例如,一项重要研究表明,以”深呼吸,逐步解决这个问题”开始提示词可以显著提高问题解决效率。这凸显了精心选择的语言对生成式 AI 系统性能的影响。
随着 AI 技术的快速发展,掌握提示词的最有效使用是一个持续的挑战。你应该认识到提示词工程的重要性,并考虑利用社区和研究的见解来改进提示词创建策略。
关键组成部分
开发提示词时,整合以下关键组件以确保清晰性和有效性非常重要:
指令(Instructions): 向 AI 提供清晰直接的指令,就像你与人沟通一样。这种清晰度对于帮助 AI”理解”期望什么至关重要。
外部上下文(External Context): 在必要时包含相关背景信息或 AI 响应的具体指导。这种”外部上下文”为提示词设定了框架,帮助 AI 掌握整体场景。
用户输入(User Input): 这是最直接的部分——构成提示词核心的用户直接请求或问题。
输出指示器(Output Indicator): 这个方面可能比较棘手。它涉及指定 AI 响应的期望格式,例如 JSON。但是,请注意,AI 可能并不总是严格遵守这种格式。例如,它可能在实际 JSON 数据之前添加”这是你的 JSON”之类的短语,或者有时生成不准确的类 JSON 结构。
提供示例
在制作提示词时,为 AI 提供预期问答格式的示例可能非常有益。这种做法有助于 AI”理解”你的查询的结构和意图,从而获得更精确和相关的响应。虽然本文档不深入探讨这些技术,但它们为进一步探索 AI 提示词工程提供了起点。
提示词应用场景
以下是进一步研究的相关资源列表:
| 应用场景 | 说明 |
|---|---|
| 文本摘要(Summarization) | 将大量文本缩减为简洁的摘要,捕捉关键点和主要思想,同时省略不太重要的细节 |
| 问答(Question Answering) | 专注于根据用户提出的问题从提供的文本中得出特定答案。这是关于针对查询精确定位和提取相关信息 |
| 文本分类(Text Classification) | 将文本系统地分类为预定义的类别或组,分析文本并根据其内容分配到最合适的类别 |
| 对话(Conversation) | 创建交互式对话,使 AI 能够与用户进行来回沟通,模拟自然的对话流程 |
| 代码生成(Code Generation) | 基于特定用户需求或描述生成功能性代码片段,将自然语言指令转换为可执行代码 |
| 零样本/少样本学习(Few-shot Learning) | 使模型能够以最少甚至没有特定问题类型的先前示例来做出准确预测或响应,使用学到的泛化能力理解并执行新任务 |
| 对话连贯性(Conversation Coherence) | 链接多个 AI 响应以创建连贯且上下文感知的对话。它帮助 AI 保持讨论的线索,确保相关性和连续性 |
| 推理(Reasoning) | 在这种方法中,AI 首先分析(推理)输入,然后确定最合适的行动方针或响应。它结合了理解与决策制定 |
Token 与提示词
Token 在 AI 模型处理文本的方式中至关重要,充当将单词(按我们的理解)转换为 AI 模型可以处理的格式的桥梁。这种转换分两个阶段发生:单词在输入时被转换为 token,这些 token 在输出时被转换回单词。
Tokenization(分词)——将文本分解为 token 的过程——是 AI 模型理解和处理语言的基础。AI 模型使用这种 token 化格式来理解和响应提示词。
为了更好地理解 token,可以将它们视为单词的一部分。通常,一个 token 代表大约四分之三的单词。例如,莎士比亚的全部作品总计约 900,000 个单词,将转换为约 120 万个 token。
Token 除了在 AI 处理中的技术角色外,还具有实际意义,特别是在计费和模型能力方面:
计费(Billing)
AI 模型服务通常基于 token 使用量进行计费。输入(提示词)和输出(响应)都计入总 token 数,因此较短的提示词更具成本效益。
模型限制(Model Limits)
不同的 AI 模型具有不同的 token 限制,定义了它们的”上下文窗口”——即它们一次可以处理的最大信息量。例如:
| 模型 | Token 限制 |
|---|---|
| GPT-3 | 4K tokens |
| Claude 2 | 100K tokens |
| Meta Llama 2 | 100K tokens |
| 部分研究模型 | 最高 100 万 tokens |
上下文窗口(Context Window)
模型的 token 限制决定了它的上下文窗口。超过此限制的输入不会被模型处理。发送最小有效信息集进行处理至关重要。例如,当询问有关”哈姆雷特”的问题时,无需包含莎士比亚所有其他作品的 token。
响应元数据(Response Metadata)
AI 模型响应的元数据包含使用的 token 数量,这是管理使用量和成本的重要信息。
Microsoft 提示词工程框架
Microsoft 提供了一个结构化的方法来开发和优化提示词。该框架指导用户创建有效的提示词,以从 AI 模型中引出期望的响应,优化交互的清晰度和效率。
💡 提示: 在设计和优化提示词时,建议参考 Microsoft 的提示词工程指南以及社区中的最佳实践,持续提升提示词的质量和效果。